目录
像Suno、海绵音乐这些AI音乐产品,一般都是生成个音频或视频文件而已,但很多时候是不够用的。
为了进一步编辑生成的AI音乐,我们往往还需要提取出AI音乐中的分轨。当我们把分轨提取出来之后,这个二次创作的想象空间就大了很多了,比如提取出伴奏带去二次录音等等。我制作分轨的目的,主要是为了提取出AI音乐的主旋律。把提取出来的主旋律转换成MIDI,再去制谱或者局部调整。
那么如何从AI音乐的音频中提取出分轨呢?我找到了3种方法。
剪映
第一种方式,是使用剪映。
做短视频的自媒体人,几乎都有剪映吧?如果你有剪映会员,又只是需要简单提取人声和伴奏带而已,那你用剪映是很方便的。
- 新建一个剪映工程,把AI音乐的音频拖进工程的轨道。
- 选择轨道上的音频,右键菜单选择
人声分离->仅保留人声。
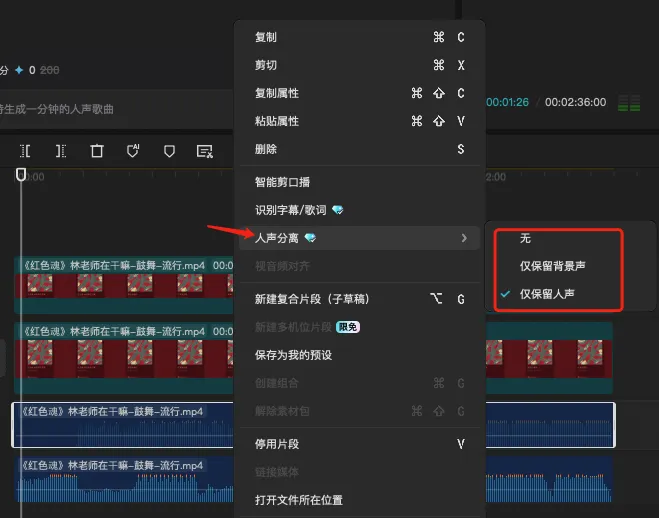
- 等待剪映处理完后,就得到一条仅保留人声的音频分轨。
- 选择导出。在导出配置中,仅勾选
音频导出,然后导出。
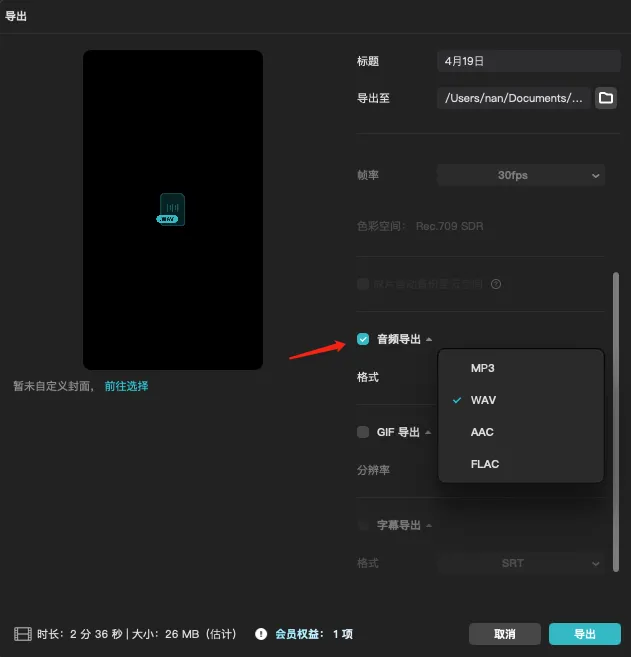
这样,你就得到纯人声的音频了。
用同样的步骤,在人声分离的时候,选择仅保留背景声,最后导出就得到了去除人声的伴奏带。
Tips:如果你的AI音乐是个视频(有一段时间,海绵音乐只提供下载视频选项,不知道是出bug了还是怎么回事),也可以先拖到剪映的轨道上,做一次分离音频操作就可以拿到音频了。
剪映的人声和伴奏带分离的效果,质量很高。缺点是得充会员,而且只能分离人声和伴奏两个分轨。
2. FL Studio
第二种方式,使用FL Studio。

FL Studio是一款功能强大的数字音频工作站(DAW)软件,俗称水果软件。它非常专业,提取分轨这种小事情,当然也可以。方法如下:
- 新建个空白的FL Studio工程,将音频拖到播放列表上。
- 点击音频片段左上角的菜单按钮,选择
Extract stems from sample。
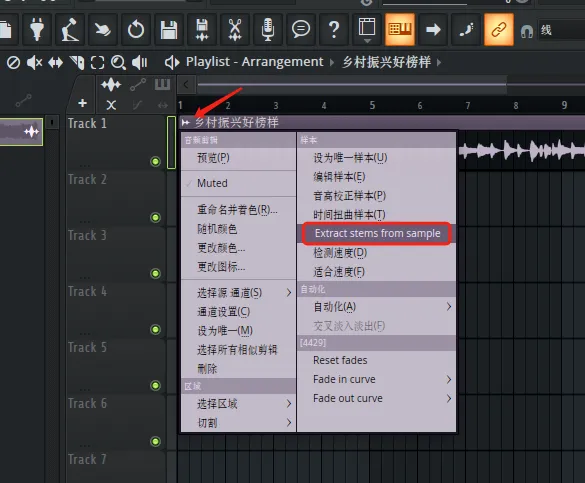
- 在弹出来的分轨选项窗口中,勾选要提取的分轨。FL Studio最多可以提取4个分轨:鼓、贝斯、乐器和人声,一般我4个分轨都会提取出来。
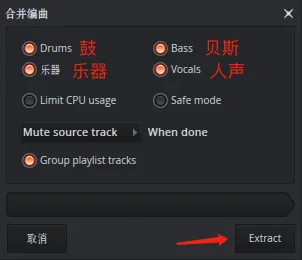
- 点击Extract按钮开始提取。首次使用这个功能要下载AI模型,需要等待一点时间,后面再次使用就很快了。提取完后,播放列表里会多出4个分轨:

- 接下来,将4个分轨分别导出,或者根据需要任意组合分轨合并导出就行。
大部分音频,使用FL Studio提取出来的分轨都很干净,效果还可以。但如果不是立志要做音乐编曲,或者做音乐工程相关的项目,我是非常不建议买这个软件的。因为,它真的非常!非常贵啊!至尊版售价要2000块,这大概是我这辈子买过最贵的软件了😢。如果你的爱好或者职业注定绕不开FL Studio这个软件,那还是闭眼买吧。买了后,就不用再花冤枉钱,去买一堆其它的AI分轨服务了。
3. Demucs-GUI
第三种方式,也是我最推荐的方式,就是Demucs-GUI。
Demucs-GUI是一个使用AI模型来提取音频分轨的开源项目,它的UI交互友好,功能很强大,重点是完全免费啊!相对于动不动几百上千的会员费和软件许可费,这简直太良心了!!
目前Demucs-GUI已经更新到1.3.2版本。1.3.2版本最多可以提取出鼓、贝斯、 人声和其它(其它指的是分离出鼓、贝斯和人声之后,剩下的部分),一共4个分轨。2.0版本还在开发中,作者是个学生,根据作者介绍,他正在训练新的AI模型,到时候可以支持提取出10个分轨。AI模型的训练成本很高,有条件的同学,也可以支持一下他。
Demucs-GUI的使用很简单,先去项目的github主页上,下载对应的软件包。考虑到在国内,github大部分时候都打不开,我已经把这个软件和一些AI模型打包放到网盘。有需要的话,可以公众号后台回复 分轨 领取。
下载后打开Demucs-GUI:
- 第一步需要选择一个AI模型,然后点击加载按钮加载。软件提供了十几个可选的AI模型选项,经过我的尝试,软件默认自带的
htdemucs模型,以及mdx_extra模型的效果就很好。至于其它的模型,有兴趣可以自己尝试一下。
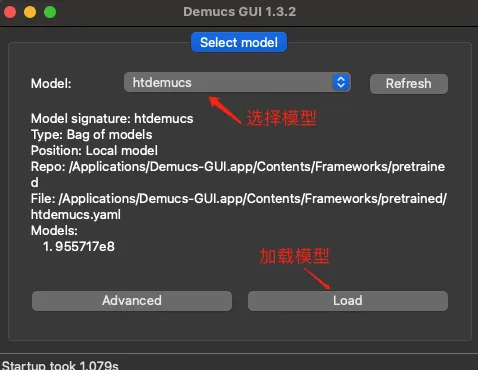
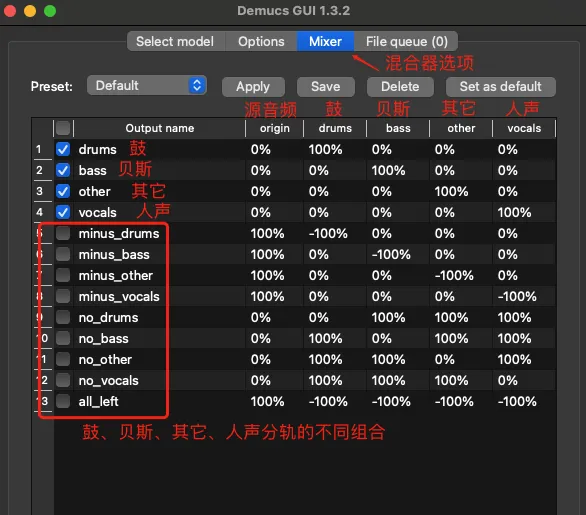
- 加载完AI模型后,会打开一个新的窗口。切换到其中的
Mixer标签,这里可以配置要提取的分轨。软件已经提供了十几个预设方案,每个方案都是按不同的比例混合鼓、贝斯、其它和人声4个分轨,具体比例可以看下图。
- 选好分轨配置之后,切换到
File queue标签,添加要提取分轨的音频源文件,可以支持一次添加多个。添加后,点击Start separation按钮,就会开始提取了。提取速度的快慢跟你电脑的硬件性能相关,你的电脑性能越强,提取速度就越快。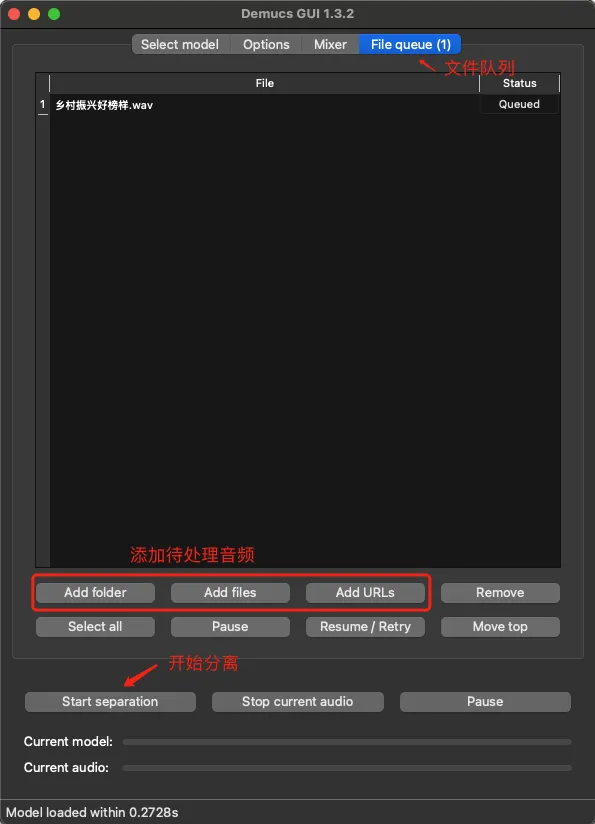
- 提取完后,默认会把分轨文件放在跟音频源文件同位置下,一个名为
separated的文件夹里面。
我测试下来,Demucs-GUI的效果,丝毫不比商业软件的差。我甚至怀疑很多买积分提取分轨的AI网站,背后会不会也是用了这个项目。搞不好……还真的有可能,哈哈哈


本文作者:Jianan
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 © 2012-2025 Jianan 许可协议。转载请注明出处!