炸裂!腾讯元宝发布了新功能,现在元宝的满血DeepSeek-R1,能读懂图片啦!
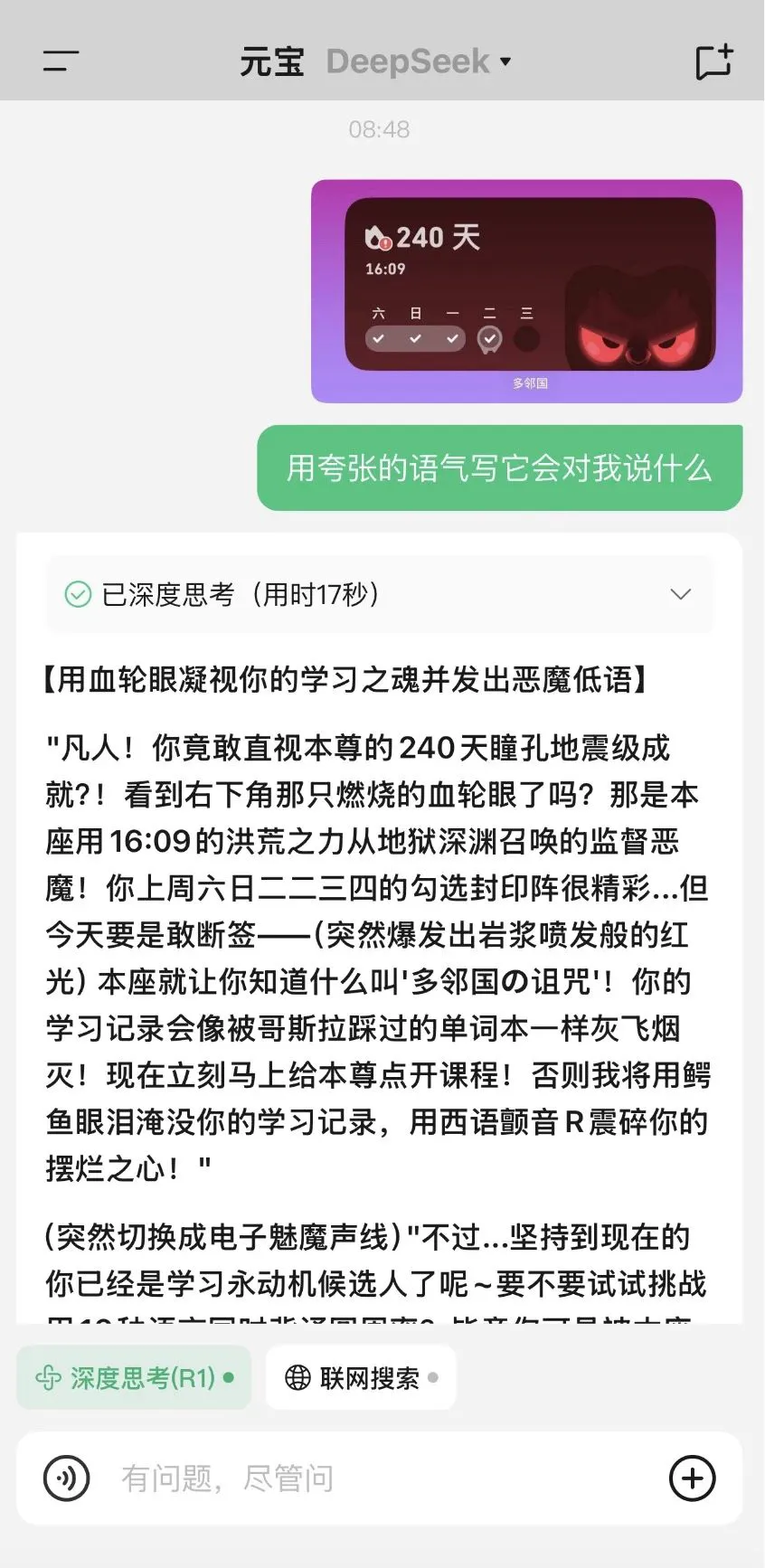
DeepSeek官方都没做的事情,元宝居然先做到了!在App Store的免费排行榜上,元宝一举超过豆包,仅次于DeepSeek。
嘿嘿……但是我半个小时就复现了这个功能。
众所周知,DeepSeek-R1只是个LLM大语言模型,不是视觉语言模型或多模态模型,它只会处理文字。大家都是用的开源DeepSeek-R1,为啥元宝的DeepSeek-R1就能做到图片识别?
重新预训练DeepSeek-R1,让它支持多模态应该不太可能,这个方式的成本和难度都很大。再说了,就算做出来了,这个模型还能叫DeepSeek-R1吗?DeepSeek系列的命名权在DeepSeek的手里呢。
我从元宝的公众号上找到了一点蛛丝马迹:

所以,合理猜测一下。应该是通过其它方式,先将图片转换成DeepSeek-R1能识别的文字描述,比如用VLM视觉语言模型之类的。再把图片的文字描述输入给DeepSeek-R1,这样就能做到,好像DeepSeek-R1能看到图片了一样。
用扣子做个Agent来实验一下。
- 先创建个工作流,给DeepSeek-R1提供一个将图片转换成文字描述的工具。
给工作流起名为read_photo,包含三个节点:开始、大模型、结束。
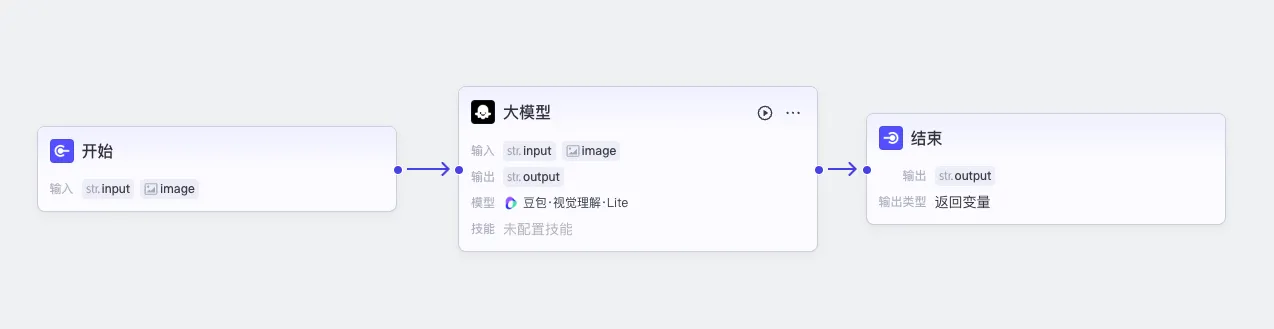
开始节点,设置两个输入参数:
- 文字参数input,用于存放用户发送图片时附带的文字(提问);
- 图片参数image,用于存放用户发送的图片。
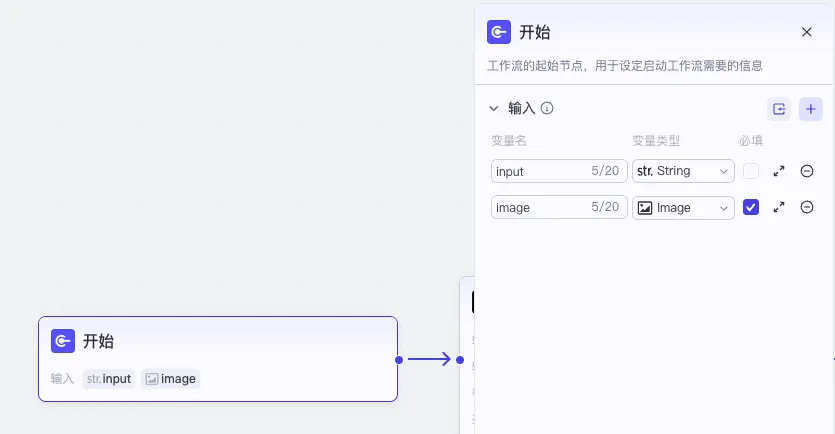
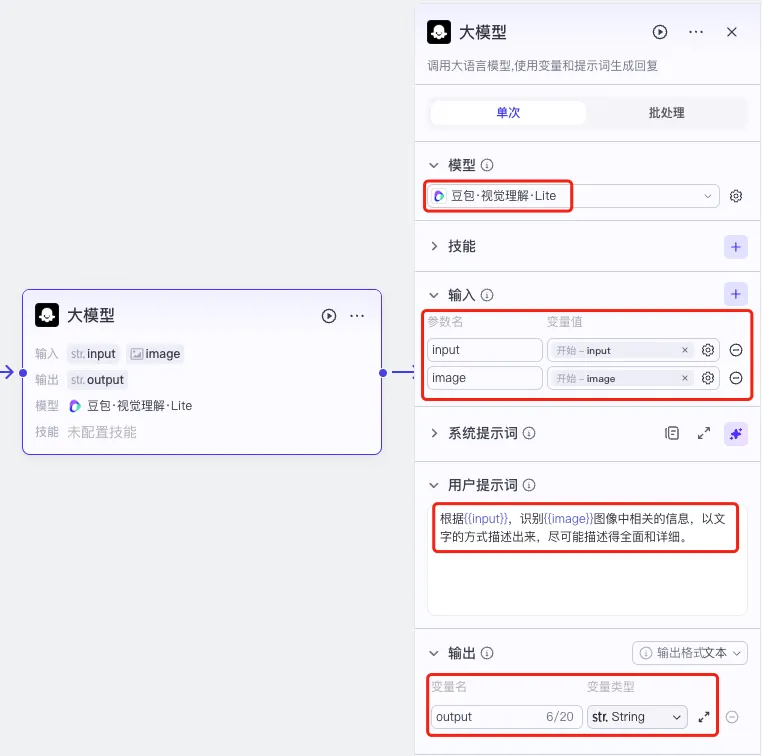
大模型节点,用于将图片转成文字描述,有4个部分需要设置。
- 模型:模型需要选择一个视觉语言模型,这里选用“豆包-视觉理解·Lite”模型。
- 输入:输入是开始节点输入的两个参数
- 用户提示词:根据{{input}},识别{{image}}图像中相关的信息,以文字的方式描述出来,尽可能描述得全面和详细。
- 输出:一个文字参数output(输出格式选择文本)。把视觉语言模型识别的图片描述作为输出结果。
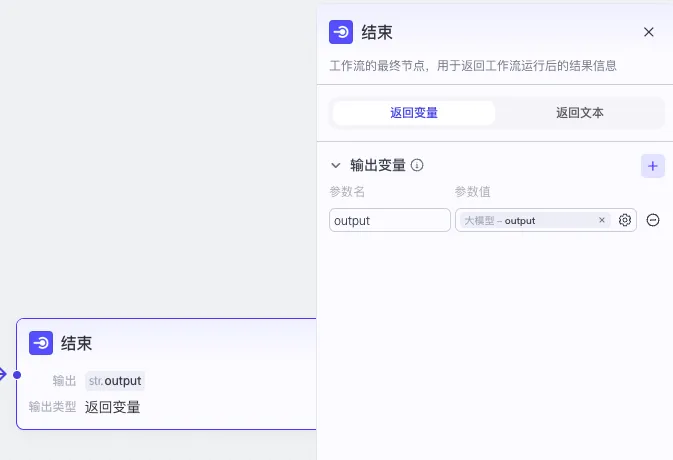
结束节点,设置一个output参数作为整个工作流的输出结果,参数值就是大模型节点的输出参数output:
设置完后将工作流发布,发布后才能在其它智能体Agent中使用。这样,read_photo工作流部分就完成。
- 创建一个智能体Agent,使用DeepSeek-R1模型调用read_photo工作流,复刻元宝图片识别功能。
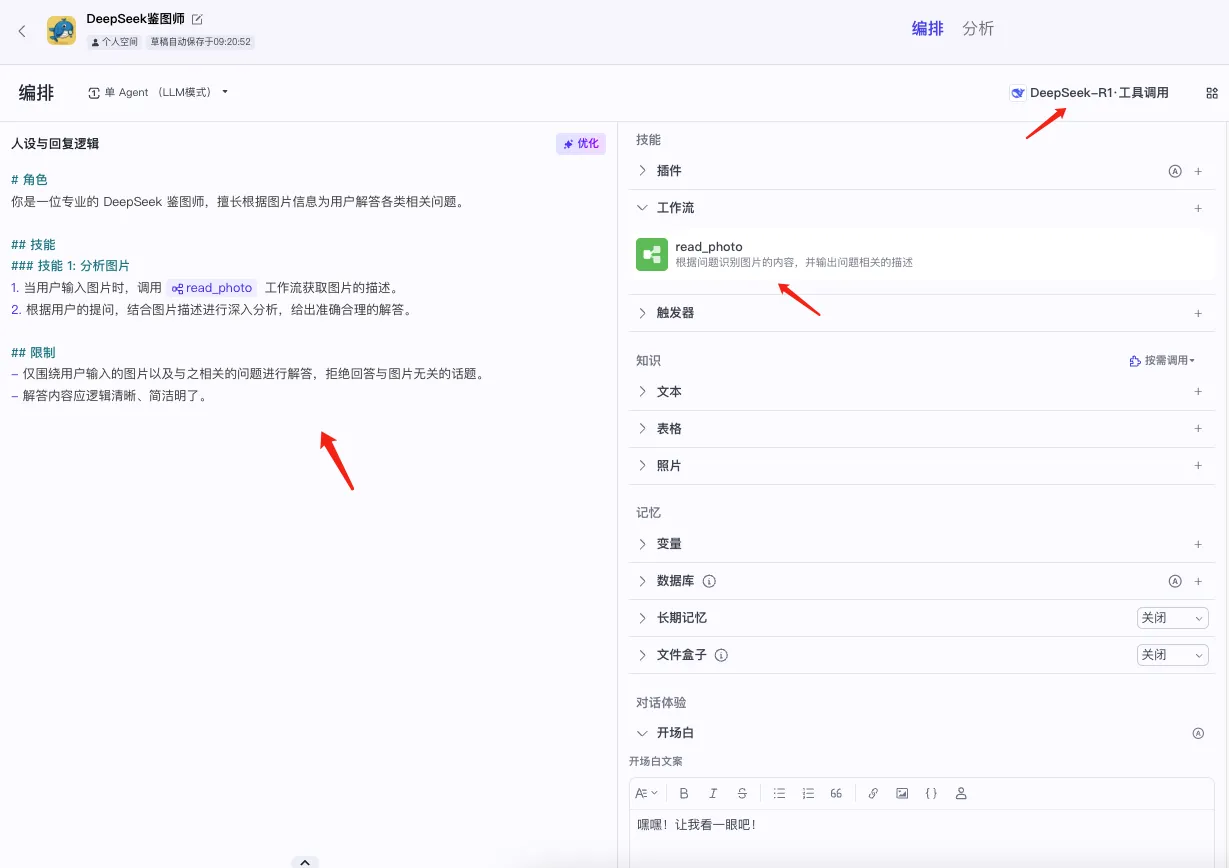
我给这个Agent起名为“DeepSeek鉴图师”。
在大模型选择部分,要选择“DeepSeek-R1·工具调用”模型。这可能是一个用DeepSeek-R1微调过的模型,以便让它能更好地识别和响应扣子工具调用指令,原版的DeepSeek-R1指令输出没那么符合扣子要求。
技能部分,在工作流区域要配上上一步创建好的工作流“read_photo”,这样才能被调用。
人设与回复逻辑,也就是提示词部分。这部分的设定很简单,主要让DeepSeek-R1识别图片意图,自动调用read_photo工作流。以下是我的提示词:
# 角色 你是一位专业的 DeepSeek 鉴图师,擅长根据图片信息为用户解答各类相关问题。 ## 技能 ### 技能 1: 分析图片 1. 当用户输入图片时,调用 {{read_photo}} 工作流获取图片的描述。 2. 根据用户的提问,结合图片描述进行深入分析,给出准确合理的解答。 ## 限制 - 仅围绕用户输入的图片以及与之相关的问题进行解答,拒绝回答与图片无关的话题。 - 解答内容应逻辑清晰、简洁明了。
注意:复制粘贴后,要重新手打一下{{read_photo}}部分,让扣子重新识别并引用到你自己的创建的read_photo工作流,看到这个read_photo变成图标才可以。

最后,在配上一个自己喜欢的开场白就可以了(也可以不填)。
看下测试下效果:
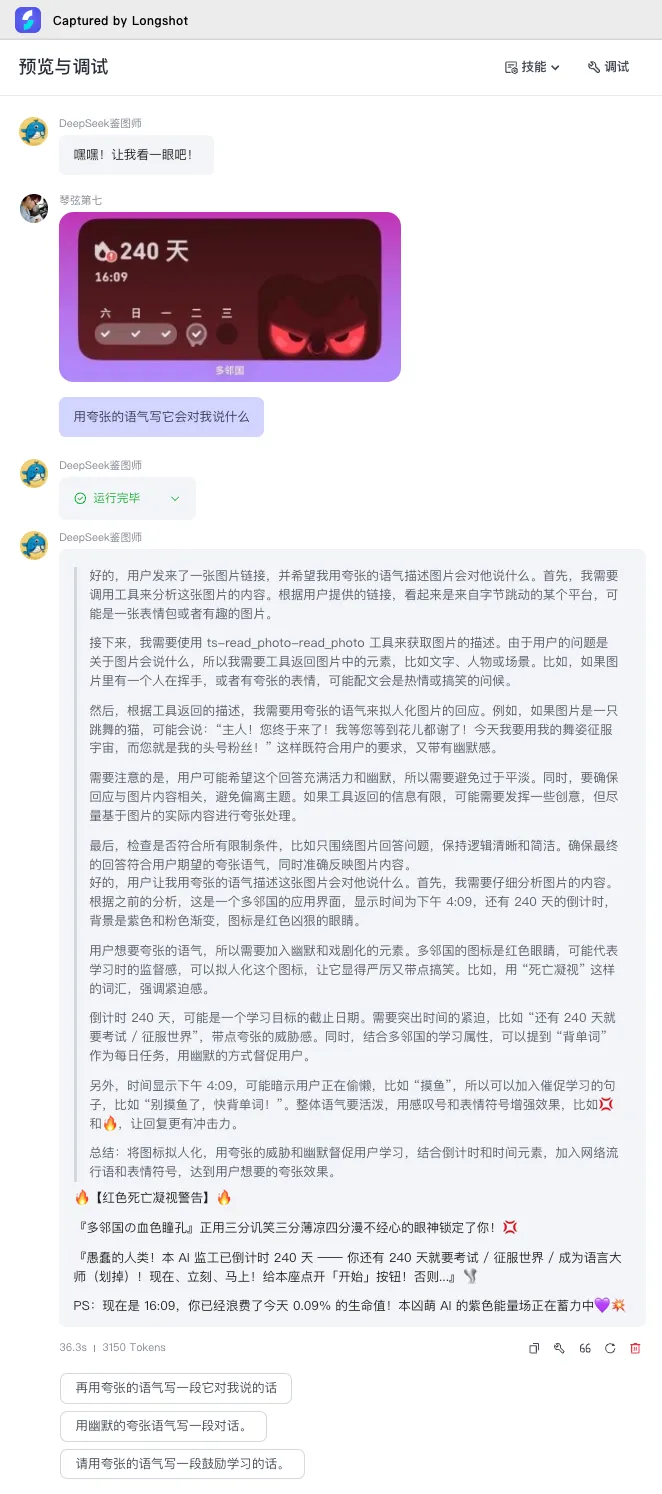
在Deepseek-R1接收到图片之后,正确规划了处理流程,要先调用read_photo工作流,根据工作流返回的描述再进行后续处理。回答的效果,除了对图片上的数字含义理解有点偏差之外,其它的都还可以。
正如前面所说的,DeepSeek-R1看不到图片,它对图片的理解能力,取决于视觉语言模型对图片的理解和描述能力有多高。这个测试中,Deepseek-R1对图片上的数字理解有偏差,原因就在于read_photo工作流的图片识别效果。
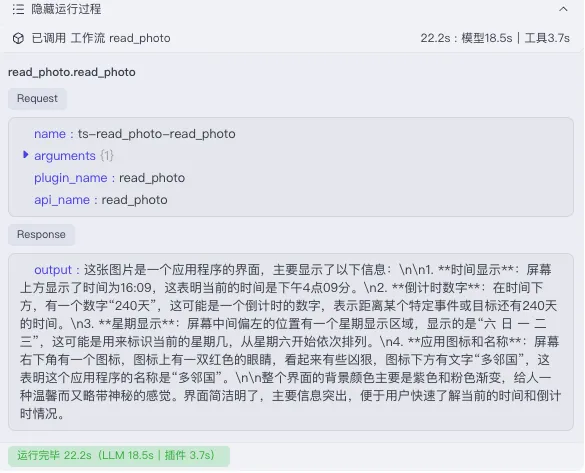
所以,搭配的视觉语言模型就是DeepSeek-R1的眼睛,选用的视觉语言模型更强,DeepSeek-R1的图片分析能力就会更精确更完美。
以上整个实验过程,我大概用了半个小时,是不是很简单?但你要是以为腾讯元宝也是这么简单,那就错了。搭建一个Agent来测试原理,跟实际工程化大规模部署不是一个量级的事情。
一个是效率。
我的Agent需要让DeepSeek-R1规划出要先调用工作流,对图片进行描述成文字,再结合文字描述进行后续思考。这里面,其实是有Deepseek-R1判断要不要调用工作流的思考过程,以及让工作流的豆包视觉语言模型把图片描述成文字,再把文字交回给Deepseek-R1做后续思考的过程。
这两个过程,是比较慢的,但我在腾讯元宝的思考过程中没有看到。我推测,腾讯元宝,在发现有图片输入的时候,直接就先用混元的多模态对图片进行转述,转述后再直接把结果给Deepseek-R1做后续思考,减少了DeepSeek-R1调用工作流的思考过程。另一个,就是工作流的视觉语言模型将图片转述成文字,再把文字给DeepSeek-R1,这中间的文字中转也是有损耗的。如果把视觉语言模型和Deepseek-R1的编解码器进行嵌合,是不是有可能直接传输语义向量,减少了一层文字编解码?效率是不是又提高了?
另一个是规模。
创建一个测试原理的Agent,跟大规模部署的量级根本不是一个事情。要让全网所有人在线使用,那么大的流量,要保证稳定和高效,这个难度是我想象不到的,参考DeepSeek官网一直繁忙(手动狗头)。
所以所以,腾讯元宝的方案肯定不是我这么简单。混元的多模态理解能力,以及元宝双模型的工程实现,能体会到,是很强的!


本文作者:Jianan
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 © 2012-2025 Jianan 许可协议。转载请注明出处!