目录
DeepSeek开源狂奔了一周,整整5天,每天开源的都是核弹级别的东西,AI圈子都快被捅破天了。但我更想知道的是,这和我有什么关系吗?
先回顾下这5天DeepSeek开源了啥?
Day1:FlashMLA,GPU算力的“涡轮增压器”
首日开源了FlashMLA。
项目地址:https://github.com/deepseek-ai/FlashMLA
FlashMLA是专为Hopper GPU优化的高效MLA(多层注意力机制)解码内核,针对可变长度序列的动态资源分配设计,突破了传统算力瓶颈。在H800 GPU上实现了3000GB/s内存带宽和580TFLOPs计算性能。
怎么做到的?
- 低秩联合压缩:将键和值矩阵压缩成低维潜在向量,减少内存占用,KV缓存需求减少了93.3%,并通过升维恢复技术保持信息完整。
- 潜在空间中的注意力计算:把输入序列映射到低维潜在空间执行注意力计算,降低计算复杂度,计算后再映射回原始空间,保留语义信息。
- 硬件感知优化:针对NVIDIA Hopper架构GPU优化,利用Tensor Core加速矩阵运算,采用BF16数据格式,提升内存和计算效率,在H800 GPU上每秒可处理3000GB 数据、执行580万亿次浮点运算。
- 动态序列处理:支持变长序列高效处理,在实际应用中减少长序列计算和内存开销,保持推理性能。
我的理解:通过算法和架构的优化,往死里榨干硬件的算力。在提高算力的策略上,除了堆硬件之外,提供了一种新思路。我也好想试试,但前提是你得有Hopper架构的GPU,比如H800(手动狗头)。
Day2:DeepEP,MoE模型的“高速公路”
第二天开源了DeepEP。
项目地址:https://github.com/deepseek-ai/DeepEP
DeepEP是一款专为混合专家模型(MoE)设计的分布式通信库,旨在解决MoE模型在分布式训练与推理中的通信瓶颈问题。其核心目标是通过优化GPU间的数据传输效率,降低延迟并提升吞吐量,从而加速大规模AI模型的开发与应用。
怎么做到的?
- 异构网络通讯适配:节点内利用NVLink高带宽快速交换数据,节点间借助RDMA降低网络延迟。DeepEP还针对节点内和节点间场景,分别提供高吞吐量、低延迟的all-to-all GPU内核优化。
- 支持低精度运算:原生支持FP8等低精度格式,降低通信数据量和计算成本,保障MoE模型高效运行,同时还能维持模型精度。
- 双模式内核支持:高吞吐量内核适用于训练和预填充阶段,可处理大批量数据;低延迟内核用于推理解码阶段,减少单次通信延迟,满足实时应用需求。
- 灵活资源控制:支持对SM数量的控制,用户能根据任务动态调整GPU资源分配,在混合负载场景中优势明显。
- 通信计算重叠:基于钩子的机制实现通信-计算重叠,在不额外占用SM资源的情况下并行处理数据传输和计算,进一步提高效率。
我的理解:DeepEP是首个面向MoE的开源通信库,填补了社区空白。而且真离谱,DeepSeek为了提高通讯效率,居然连内核都写!这样的内核我也想体验一下,但是,H800集群……想想就很美好……
Day3:DeepGEMM,矩阵计算的“极致美学”
第三天开源了DeepSeekGEMM。
项目地址:https://github.com/deepseek-ai/DeepGEMM
DeepGEMM是一个FP8通用矩阵乘法(GEMM)计算库,目前仅支持NVIDIA Hopper架构GPU。整个库核心代码只有300行左右,最高可达1350+ FP8 TFLOPS,超越了大多数人工专家的调优。
怎么做到的?
- DeepGEMM中的内核是warp专用的,支持重叠数据移动、张量核心MMA指令和CUDA核心提升。
- 利用了Hopper的TMA特性,实现更快的异步数据移动。
- 使用了stmatrix PTX指令、为不同的warpgroup量身定制计数控制、尽可能重叠等常见细节优化。
- 构造了一个统一且优化过的区块调度器。适用于所有非分组和分组内核,并且栅格化以增强L2缓存重用。
- 采用完全JIT设计,安装时无需编译,运行时编译内核,能显著提升小形状矩阵计算性能。
- 支持未对齐块大小。
- FFMA SASS交错优化
我的理解:矩阵计算是大模型训练和推理过程中,算力最大的消耗点。只要把力气使在关键位置上,“小力也能出奇迹”,大幅度提升了整个系统框架的计算效率!不过,这个库同样也是需要Hopper架构的GPU才能支持……
Day4:并行优化策略,训练效率的“时间刺客”
第四天一口气开源了3个工具:
- DualPipe:一种创新的双向管道并行算法。项目地址:https://github.com/deepseek-ai/DualPipe。它实现了前向和后向计算通信阶段的完全重叠,还减少了管道气泡,相比传统算法,在减少设备空闲时间上优势显著。
- EPLB:即专家并行负载均衡器。项目地址:https://github.com/deepseek-ai/eplb。它实现了“冗余专家”策略,提供层次化和全局两种负载均衡策略,还能减少跨节点数据传输。
- Profile-data:该项目开源训练和推理框架的性能分析数据,可在浏览器可视化,展示了计算与通信重叠策略的效果。项目地址:https://github.com/deepseek-ai/profile-data
我的理解:第四天开源东西,主要是从工程化的角度来提升计算效率。它通过算法,尽可能让计算并行,目的就是让每个计算节点都给我往死里干,一刻都不准停下来!典型的算力“黑心老板”啊!
Day5:3FS文件系统,数据存取的“光速引擎”
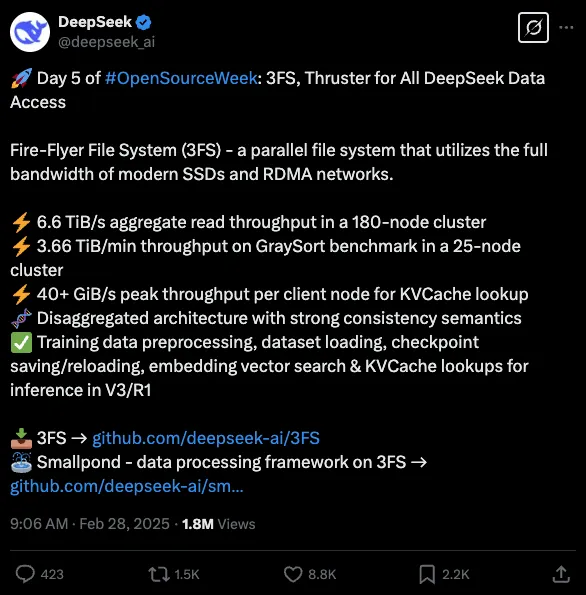
第五天开源了3FS文件系统和Smallpond数据处理架构。
-
3FS文件系统,是一款高性能分布式文件系统,专为AI训练和推理设计,通过整合现代SSD和RDMA网络带宽,提供共享存储层以简化分布式应用开发。它在大型集群读压力测试中,总读取吞吐量达约6.6TiB/s;使用GraySort基准测试,在25个存储节点和50个计算节点的集群上,平均吞吐量为3.66TiB/min;KVCache 客户端读取峰值吞吐量可达到40GiB/s。
项目地址:https://github.com/deepseek-ai/3FS -
Smallpond,是一个基于DuckDB和3FS构建的轻量级数据处理框架。它在DuckDB的支持下,具备高性能数据处理能力;可扩展性强,能处理PB级数据集;操作简便,无需长期运行服务。在由50个计算节点和25个存储节点运行3FS的集群上,使用GraySort基准测试评估,30分14秒内排序110.5TiB 数据,平均吞吐量达到3.66TiB/min。
项目地址:https://github.com/deepseek-ai/smallpond
我的理解:太疯狂了!deepseek为了计算效率,居然连分布式文件系统这种基础组件都去做,而且还做到了领先,这是一般团队能做出来的吗?我想起来我书架上积灰好几年的《深入浅出SSD》,翻了一下,还是没有耐心看下去。在没有明确目标和预期效益的情况下,有谁会愿意去做这种基础研究呢?吃力不讨好啊。
总结
deepseek这5天开源的项目看似很杂,好像不是一个AI大模型团队应该去做的事情。但如果你从一个工程师团队的角度去看,那不过是为了实现既定的目标,在工程实现的过程中,把遇到的问题逐个解决掉而已。不是一开始就计划去做这些项目,而是这些问题阻碍到我了,我只好把它解决掉,开源出来的这些项目只是个顺带的结果。只不过deepseek比较硬核,居然在各个方面都做到了极致(这是什么神仙团队?!)。
这些项目,总体上都离不开“效率”和“成本”。deepseek追求极致的效率和最低的成本,可能是因为“现实”环境不得不这么做,也可能是商业上的考虑,总之就是这么做了。而开源出来的这些技术,对于我们这些下游的应用开发者和C端用户来说,其实很难直接用得上。它们更多的是集中在AI产业链的上游,对上游的AI模型厂商和服务商产生影响,最直接的影响就是它会把AI模型的价格打下来。
deepseek在开源的第6天就公布了它的成本和理论收入,在保持低价的同事,理论上的成本利润率居然还可达到545%。是不是很意外?
试想一下,AI厂商的API价格越来越低,当有一天变成白菜价的时候,会发生什么呢?很多原来跑不通的商业模型就能跑的通了!这会大大刺激下游产业,各行各业的AI应用也许会跟雨后春笋一样冒出来,最终是AI像水煤电一样的普及和整个社会效率的提升。
可能,这一天很快就会到了。


本文作者:Jianan
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 © 2012-2025 Jianan 许可协议。转载请注明出处!